Prawdopodobnie potrzebujesz reprezentacji przedziału ufności dla szacowanego ctr. Wilson score interval jest dobrym rozwiązaniem.
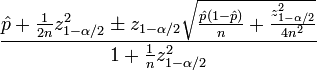
trzeba poniżej statystyki obliczyć wynik ufności:
\hat p jest obserwowana CTR (frakcja #clicked vs #impressions)n jest całkowitą liczbą wrażeńz α/2 jest kwantylem standardowym nr (1-α/2) Rozkład mal
prosta implementacja, w pytona przedstawionym poniżej użyć z (1-α/2) = 1,96, co odpowiada 95% przedziału ufności. Dołączyłem 3 wyniki testu na końcu kodu.
# clicks # impressions # conf interval
2 10 (0.07, 0.45)
20 100 (0.14, 0.27)
200 1000 (0.18, 0.22)
Teraz można ustawić próg, aby użyć obliczonego przedziału ufności.
from math import sqrt
def confidence(clicks, impressions):
n = impressions
if n == 0: return 0
z = 1.96 #1.96 -> 95% confidence
phat = float(clicks)/n
denorm = 1. + (z*z/n)
enum1 = phat + z*z/(2*n)
enum2 = z * sqrt(phat*(1-phat)/n + z*z/(4*n*n))
return (enum1-enum2)/denorm, (enum1+enum2)/denorm
def wilson(clicks, impressions):
if impressions == 0:
return 0
else:
return confidence(clicks, impressions)
if __name__ == '__main__':
print wilson(2,10)
print wilson(20,100)
print wilson(200,1000)
"""
--------------------
results:
(0.07048879557839793, 0.4518041980521754)
(0.14384999046998084, 0.27112660859398174)
(0.1805388068716823, 0.22099327100894336)
"""
{kind=link}
{kind=link}
Dzięki za odpowiedź. Ale chcę wiedzieć, czy istnieje statystyczna metoda znormalizowana pod względem wyświetleń, a nie pewność dla szacowanego ctr. Na przykład ta metoda może wyglądać następująco: # (kliknij) * 2/(# (wyświetlenia) + średnia (#impressions)) – Tim
Właściwie nie jestem pewien, czy rozumiem, czego chcesz i dlaczego chcesz tego dokonać. A co z estymatorem Bayesa? Lub coś w rodzaju wyniku IMDB? http://en.wikipedia.org/wiki/Bayes_estimator – greeness
Czy z = 1,6 nie odpowiada 90% pewności? Google helper: https://www.google.ru/search?q=z+values+confidence, artykuł dla manekinów :-): http://www.dummies.com/how-to/content/finding-appropriate- zvalues-for-given-confidence-l.html – skaurus