Wygląda na to, że istnieje kilka opcji dostępnych dla programów obsługujących dużą liczbę połączeń z gniazdami (takich jak usługi sieciowe, systemy p2p itp.).Jak najlepiej radzić sobie z dużą liczbą deskryptorów plików?
- Nawiązać osobny wątek do obsługi wejść/wyjść dla każdego gniazda.
- Użyj wywołania systemowego select, aby zmultipleksować wejścia/wyjścia w pojedynczy wątek.
- Użyj wywołania systemowego poll, aby zmultipleksować wejścia/wyjścia (zastępując wybór).
- Użyj wywołań systemowych epoll, aby uniknąć konieczności wielokrotnego wysyłania gniazd fd przez granice użytkownika/systemu.
- Zajarzenie liczby wątków we/wy, które każdy multipleksuje stosunkowo mały zestaw całkowitej liczby połączeń za pomocą interfejsu API ankiety.
- Zgodnie z # 5, za wyjątkiem korzystania z epoll API do tworzenia oddzielnego obiektu epoll dla każdego niezależnego wątku we/wy.
W procesorze wielordzeniowym spodziewałbym się, że najlepsze wyniki będą miały numery 5 lub 6, ale nie mam żadnych twardych kopii zapasowych danych. Przeszukując stronę internetową, pojawiła się strona opisująca doświadczenia autora testującego podejścia # 2, # 3 i # 4 powyżej. Niestety strona ta ma około 7 lat i nie można znaleźć żadnych oczywistych najnowszych aktualizacji.
Moje pytanie brzmi, które z tych podejść okazały się najbardziej skuteczne i czy istnieje inne podejście, które działa lepiej niż którekolwiek z wymienionych powyżej? Należy docenić odwołania do rzeczywistych wykresów, oficjalnych publikacji i/lub internetowych publikacji.
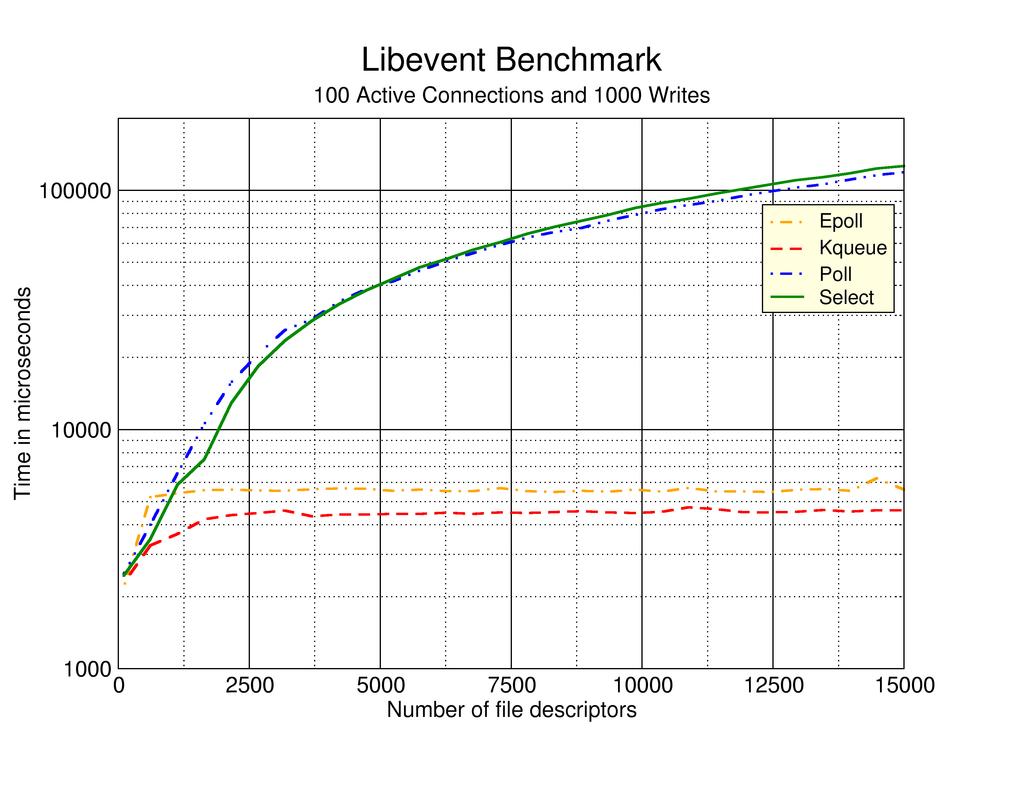 .
.
Myślę, że jest to rozwiązany problem, a odpowiedź jest tutaj - http://www.kegel.com/c10k.html – computinglife