7
Mam listę tekstowych tokenized (list_of_words), który wygląda mniej więcej tak:Jak usunąć termin z listy w Pythonie
list_of_words =
['08/20/2014',
'10:04:27',
'pm',
'complet',
'vendor',
'per',
'mfg/recommend',
'08/20/2014',
'10:04:27',
'pm',
'complet',
...]
i staram się rozebrać wszystkie instancje datami i czasem z tej listy. Próbowałem użyć funkcji .remove(), bez rezultatu. Próbowałem przekazywać znaki wieloznaczne, takie jak "../../...." do listy słów, które sortowałem, ale to nie zadziałało. W końcu próbowałem napisać następujący kod:
for line in list_of_words:
if re.search('[0-9]{2}/[09]{2}/[0-9]{4}',line):
list_of_words.remove(line)
ale to też nie działa. Jak mogę usunąć wszystko z datą sformatowaną na podstawie daty lub czasu?
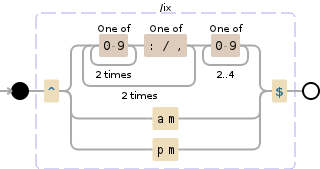

Czy istnieje szczególności Format danych i/lub czasu, który chcesz usunąć? – mng