51
Mam dwa pliki A - nodes_to_delete i B - nodes_to_keep. Każdy plik ma wiele wierszy z numerycznymi identyfikatorami.bash, Linux: Ustaw różnicę między dwoma plikami tekstowymi
Chcę mieć listę numerycznych identyfikatorów, które są w nodes_to_delete, ale NIE w nodes_to_keep, np. alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
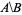{kind=link}
Robiąc to w bazie danych PostgreSQL jest nierozsądnie wolny. Czy można to zrobić za pomocą narzędzi Linux CLI?
AKTUALIZACJA: Wydaje się, że to praca Pythonica, ale pliki są naprawdę, naprawdę duże. Rozwiązałem niektóre podobne problemy używając uniq, sort i niektórych technik teorii zbiorów. To było o dwa lub trzy rzędy wielkości szybsze od odpowiedników w bazie danych.
Jestem ciekaw, co przyjdzie odpowiedzi. Bash to trochę więcej segphault, uważam, że administrator systemu. Jeśli powiedziałbyś "w pythonie" lub "w php" lub cokolwiek byś nie poradził lepiej :) – extraneon
Widziałem tytuł i byłem gotowy na bip niespójności w interfejsie użytkownika oraz na bardziej holly niż na forum pomocy. To mnie rozczarowało, kiedy przeczytałem faktyczne pytanie. :( – aehiilrs